
グリム兄弟の「小人のくつ屋さん」を聞いたことがあるだろう。寝静まった真夜中に不思議な小人たちが靴を仕上げてくれる童話だ。
最近話題のAIエージェントとPlaywright MCP(ブラウザ操作MCP)は、自然言語による指示で動き、人間へ頼んだかのような感覚で、自律的にブラウザを操作してくれる。
例えば先日、AIエージェントがブラウザを操作し、ヒューリスティックなUX診断を行う例が話題になっていた。
このようなAIエージェントによるブラウザ操作とGoogleスプレッドシートと連携し、何らかのテーマで多数のサイトやページを横断的に調査するバッチ処理に仕立ててみよう。すると調査対象リストをシートに書いておけば、寝ている間にAIエージェントが働いてシートを埋めてくれる。「小人の調べ屋さん」が実現する。
そのような仕組みを Mastra を用いて実装してみた。ソースコードも公開したので、ぜひアレンジして不思議な小人を見つけてほしい。
開発したプログラム
動作の様子を録画した。8倍速で再生しているが、AIエージェントが次々とブラウザにWebページを表示し、調査結果がスプレッドシートに更新されていく様子が見て取れる。
今回の題材 「アクセスランキング利用率の調査」
弊社では任意のWebサイトにアクセスランキング機能を追加するための Rankelt4 というサービスを提供している。
それに関連し、多数のサイトを調査してアクセスランキングの利用率を調べるという業務を想定した。
- Googleスプレッドシートに書いておいたニュースサイトをひとつずつ開く
- URLが間違っていたらWeb検索をして訂正する
- アクセスランキングが表示されているかを確認する
- その結果をGoogleスプレッドシートに記入する
- 以上の処理を対象リストの分、繰り返す
アクセスランキングは「人気記事」「人気ランキング」など表記にばらつきがあるため、単純なテキスト処理では正確に判定できない。また、JavaScriptで展開されているケースもあり、HTML上の字面だけのスクレイピングでは正確な判定ができない。
そのためこれまでは人間がブラウザを目視して判断せざるを得なかった。数サイトであれば我慢できるが、数が多いと心が折れそうな単純作業である。これを小人さんたちにやってもらう。
もちろんこれはひとつの題材に過ぎず、AIエージェントに他の調査を依頼することも可能だ。
ソースコード
作成したプログラムを以下のリポジトリで公開した。詳しくはREADME.mdをご覧いただきたい。
- ideamans/mastra-ai-agent-batch-example: Mastra × PlayWright MCP × GoogleスプレッドシートによるAIエージェントのバッチ処理実装例
最低限、次のサービスと認証情報があればすぐに動作も確認できる。
- Google Cloud上のサービスアカウントとそのJSON鍵
- Google GeminiのAPIキー
- Brave SearchのAPIキー
なお、この例では安価なGeminiを利用しているが、Function Callingを備えていればChatGPTやClaudeにも容易に変更できる。
開発の流れとプログラムの解説
AIエージェントフレームワーク Mastra
LLMはパワフルだが、それ単体はあくまで脳のような器官であり、安定した仕事をするにはさまざまな支えが必要になる。Mastraは、LLMにそのような機能をまとめて用意してくれるフレームワークだ。
この手のプロジェクトで有名なのはLangChainやLangGraphで、もちろんPythonでも同様の実装は可能だろう。単に個人的なスキルセットから、TypeScriptの方が得意なのでMastraを採用した。
MCP (Model Context Protocol) サーバー
LLMとフレームワークが、さらに外部のシステムと連携するための仕組みがMCP (Model Context Protocol) サーバーである。
世の中にある既存のサービスがMCPサーバーを提供すると、AIエージェントが自律的にそのサービスも活用できるようになる。
今回は二つのMCPサーバーを用いる。
- ブラウザ操作 microsoft/playwright-mcp: Playwright MCP server LLMがブラウザを開いて自律的に利用できるようになる。
- Web検索 servers/src/brave-search at main · modelcontextprotocol/servers LLMが必要に応じてBrave SearchでWeb検索できるようになる。
Web検索はURLの訂正に用いる。バッチ処理の指示としてサイト名とURLのリストを人間が何らかの方法で用意するのだが、当然、URLを間違えることもあり得る。
人間による作業であれば、「これはURLの間違いだな。検索して訂正しておこう」と気を利かせられる。Web検索MCPサーバーによってそれを再現できる。
まずはAIエージェント単体の動作確認をする
Mastraの優れた点のひとつに、プレイグラウンドUIがある。
システムプロンプトで役割を与えたAIエージェントと対話できるチャットインターフェースをコマンドひとつで即座に起動できるのだ。
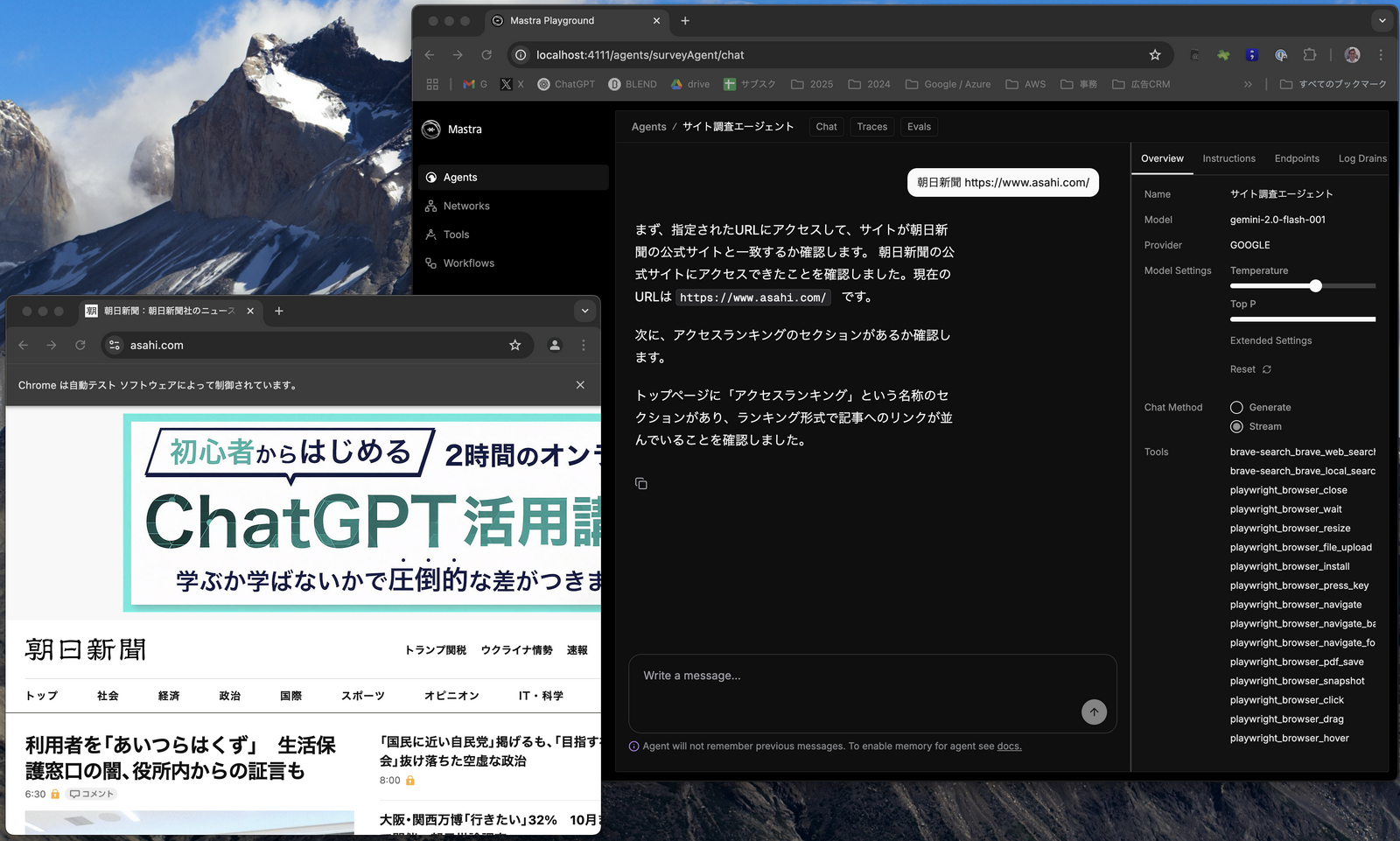
例えば、次のプロンプトを入力すると、
朝日新聞 https://www.asahi.com/Playwright MCPサーバーがブラウザで朝日新聞サイトを開き、アクセスランキングの有無を判定してくれる。
まず、指定されたURLにアクセスして、サイトが朝日新聞の公式サイトと一致するか確認します。 朝日新聞の公式サイトにアクセスできたことを確認しました。現在のURLは https://www.asahi.com/ です。
次に、アクセスランキングのセクションがあるか確認します。
トップページに「アクセスランキング」という名称のセクションがあり、ランキング形式で記事へのリンクが並んでいることを確認しました。次にわざとサイト名と違うURLを与えてみよう。
毎日新聞 https://www.asahi.com/すると、以下のような回答が得られる。「URLが違うみたいだから検索して修正するね」と働いてくれるのだ。
まず、指定されたURLにアクセスして、サイトが「毎日新聞」と一致するか確認します。
URLを開いたところ、サイトは「朝日新聞」でした。「毎日新聞」ではありませんでしたので、ウェブ検索で「毎日新聞」のURLを調べます。
検索結果から、「毎日新聞」のURLは https://mainichi.jp/ であることがわかります。ブラウザでこのURLを開きます。
URLを修正し、ブラウザで開きました。現在のURLは https://mainichi.jp/ です。
次に、アクセスランキングのセクションを確認します。
ウェブページを調べたところ、「アクセスランキング」という名称のセクションが見つかりました。このように実現したいことをすぐに試せるし、デバッグやチューニングも大変捗る。
Googleスプレッドシートとの連携
次にこのAIエージェントをバッチ処理にしていくが、バッチ処理に付きものなのがデータの入出力だ。
タスクリストをどこかで管理し、結果もどこかに出力する必要がある。
今回はGoogleスプレッドシートをドキュメントデータベース代わりに用いる。小規模のバッチ処理程度であればこのアプローチのメリットは大きい。
- 優れたGUI 慣れ親しんだ表計算GUIでデータを総覧し、その場で微調整できる。
- 前後の工程との相性 前工程(リストの準備など)や後工程(加工や集計)には結局スプレッドシートを使うことが多い。
何よりスプレッドシートが勝手に編集されていくという様に、小人の仕業のような不思議さがなかろうか。
Googleスプレッドシートを操作する代表的なNPMモジュール google-spreadsheet は、スプレッドシートをドキュメントデータベースライクに扱うための機能も提供しているので、比較的実装は容易である。
バッチ処理ワークフローを組む
以上の要素を組み合わせ、一連の処理をワークフローに落とし込んでいく。
- 残タスクの一覧をGogleスプレッドシートから読み込む
- 残タスクをひとつ取り出す
- AIエージェントに調査をさせる
- 調査結果(自然言語)をデータベース更新用の構造化データにする
- 構造化データをスプレッドシートに書き込む
- 残タスクがなくなるまで繰り返す
ワークフロー開発は、まず「ステップ」と呼ばれる各段階の部品の開発と、その接合からなる。
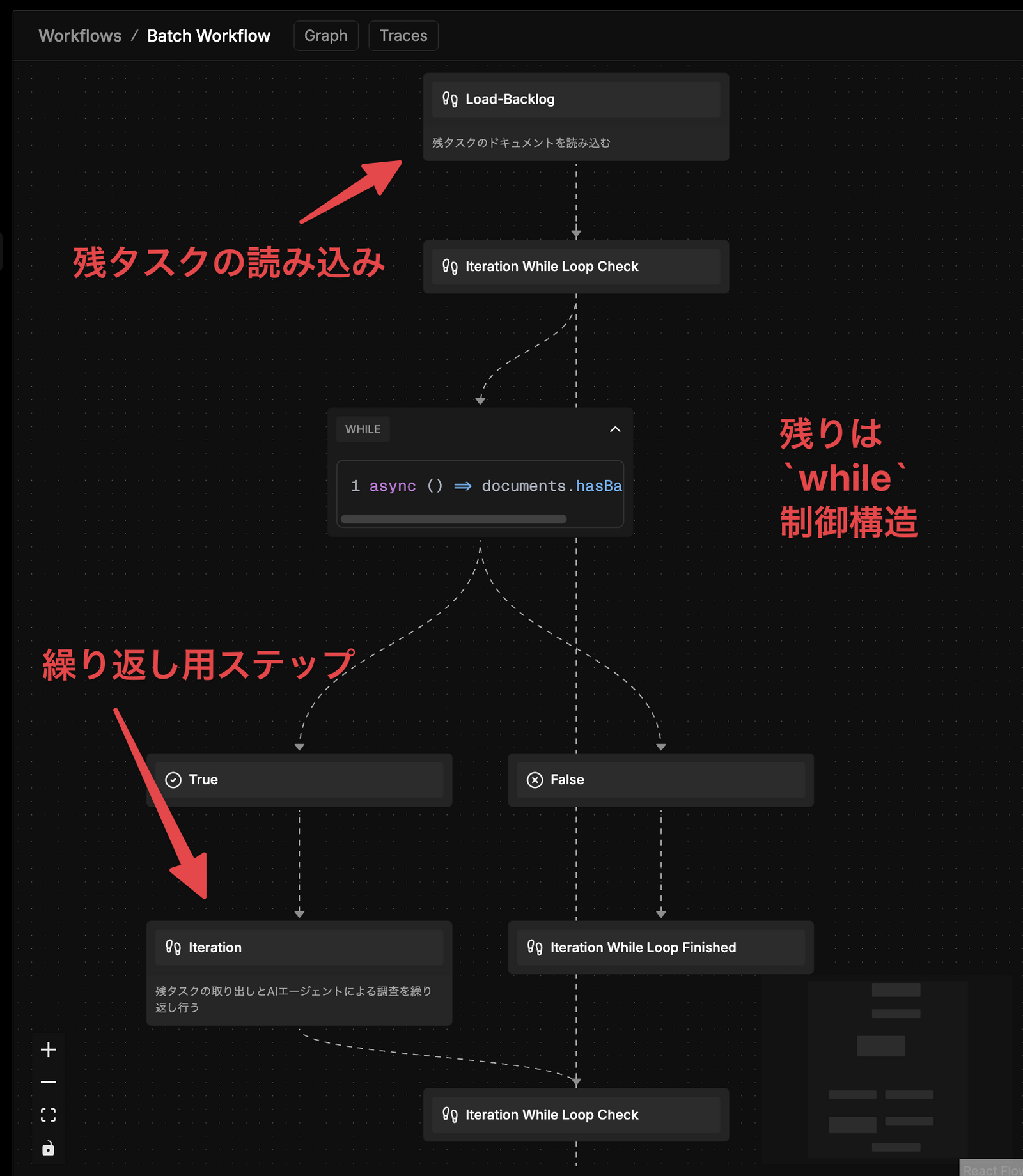
複雑に見えるが主要なステップはふたつだけで、残りは while による繰り返し制御で接合する形を示している。全体の構造としてはシンプルだ。
残タスクの読み込みステップの実装
ここではシンプルにGoogleスプレッドシートから未処理のドキュメント(残タスク)を読み込む。
ワークフローの開発中は繰り返し実行してデバッグすることになる。最初に読み込みステップを入れておくと、巻き戻しの役割も果たし、手間も減る。
繰り返し用ステップの実装
次に上記2〜5の処理をひとつの繰り返し用ステップとして実装する。ここは少しプログラミングが複雑になる。
まずは読み込み済みの残タスクからひとつを取り出し、AIエージェントにサイト名とURLを渡す。先ほどチャットインターフェースで試したように、回答が自然言語で得られる。
例えば次のようなテキストで結果が得られる。
まず、指定されたURLにアクセスして、サイトが朝日新聞の公式サイトと一致するか確認します。 朝日新聞の公式サイトにアクセスできたことを確認しました。現在のURLは https://www.asahi.com/ です。
次に、アクセスランキングのセクションがあるか確認します。
トップページに「アクセスランキング」という名称のセクションがあり、ランキング形式で記事へのリンクが並んでいることを確認しました。次にこの結果をGoogleスプレッドシートに適切に書き込むため、プログラムで扱える構造化データに変換する。これはLLMの構造化出力という機能により容易に実現できる。
{
"アクセスランキングの有無": "有り",
"アクセスランキングの名称": "アクセスランキング"
}この変換のため、サイト調査とは別に structureAgent という別のAIエージェントを用意している。
while による繰り返し
最後に、繰り返し用ステップを残タスクがなくなるまで繰り返す流れを while という制御構造で実現している。
代替案: AIエージェントによる入出力というアプローチ
今回のプログラムでは、まずLLMに調査結果を自然言語で出力させ、それをまた別のLLMで構造化データに変換する二段階の処理を経ている。
実はこれを一段階にまとめる方法がある。それがGoogleスプレッドシートの入出力をAIから利用できるよう「ツール化」するアプローチだ。
Mastraでは開発者が用意した任意のプログラムに適切なメタデータを付与し、AIエージェントがFunction Callingで利用可能にする手法がある。それが「ツール化」だ。MCPサーバーの呼び出しも一種のツールである。
そこでGoogleスプレッドシートとの入出力もツール化してしまえば、理論上はワークフローにおける実装を行う必要はなく、AIエージェントへの指示で完結する。
当初はそのアプローチで実装を進めていた。しかし、私の実装に問題があったのかもしれないが、ツールに空っぽの更新データが渡されたり、更新リクエスト自体がAIエージェントから発行されなかったりと、動作が安定しなかった。
そのため二段階方式を選択し、結果として安定した動作を示した。
AIでやること・プログラムで制御することの線引き
このように従来のプログラミングでできることを、AIに委譲すること自体は決して難しくない。
AIはトークン費用がかかり、処理も遅いという弱点はある。しかし変に処理を分割してインターフェースを増やすより、AIエージェントへの指示に包括した方が全体の見通しがよくなることもあるだろう。
今回の二段階方式には、安定性以外にもAIエージェント単体の動作確認やプロンプトチューニングが進めやすいという利点はあった。
いずれも一長一短があり、どちらでやるべきか?という線引きには今後も頭を悩ませることが多いだろうと予感している。
最後に
業界動向を語る上で「多いです!」「増えてます!」と言うのは簡単だが、データを伴わない程度表現はビジネスにおいて稚拙である。
何を根拠に多いとか増えていると言っているのか、リサーチした上で定量的なデータを示したいところだが、以前はそのための技能や人手が必須だった。
AIディープリサーチの登場で、抽象度の高い情報収集と統合は容易になった。しかしディープリサーチではまだできない調査がある。それが今回のプログラムで実現したような「緻密なフィールドワーク」である。
まず自分が使いたいプログラムを作ったのだが、他の誰かの役にも立てば幸いである。