
最近、Macbook ProをM1 ProからM4 Proにアップグレードしたので、LM Studio でローカルLLMを動かしてみたらさすがに早い。
そこに Qwen3 というまたすごそうなオープンソースのLLMが公開されたので、
Mastraに繋いでMCPサーバーを使うことを試してみた。
LM StudioをOpenAI互換APIサーバーにする
私のようなミーハーLLM使いでも最新モデルを簡単に試すことができるLM Studioという素敵なアプリケーションがある。
こちらをインストールし、次の手順でQwen3関連のLLMをダウンロードし、OpenAI互換のAPIサーバーとして使えるようにする。
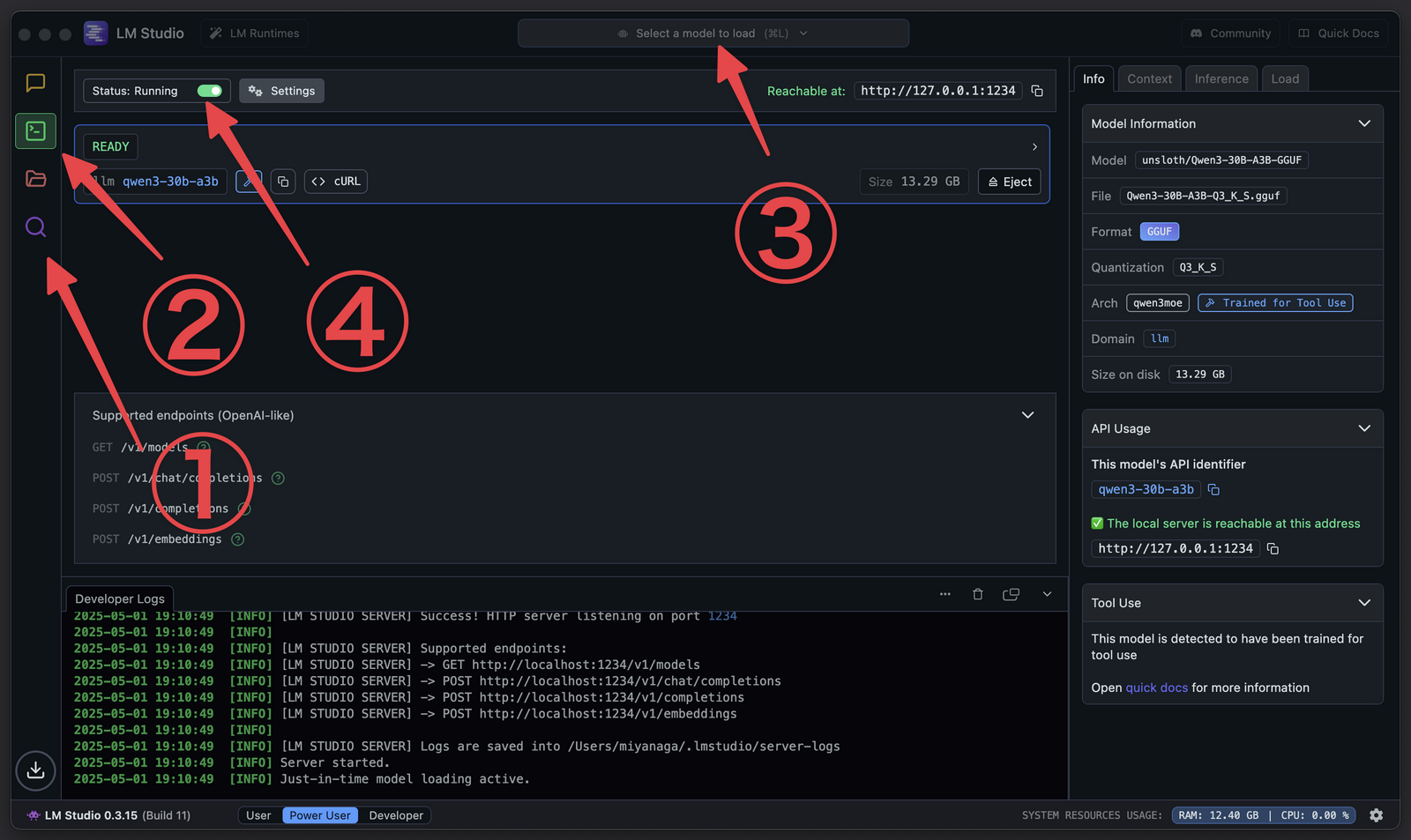
- 虫眼鏡マークでQwen3を検索してダウンロード(私は
qwen3-30b-a3bを選択した) Developerペインを選択- 上部のモデルバーからダウンロードしたモデルを選択
- トグルをオンにするとサーバーが起動。
http://127.0.0.1:1234でアクセス可能に
Mastraから使う
MastraはTypeScript製のAIエージェントフレームワークだが、以下の記事で詳しく触れたので解説は省略する。
MastraではVerselの AI SDK を採用しており、以下のように認知負荷の低い方法で各種LLMをリファレンスできる。
import { openai } from '@ai-sdk/openai'
export const model = openai('gpt-4.1-mini')AI SDKには OpenAI互換モデル という実装があり、以下のコマンドでモジュールを追加しておくと、
# モジュールを追加
pnpm add @ai-sdk/openai-compatible以下のようなコードで透過的にモデルを差し替えられる。
import { createOpenAICompatible } from "@ai-sdk/openai-compatible"
// OpenAI互換ファクトリ
const lmStudio = createOpenAICompatible({
name: 'lm-studio',
baseURL: 'http://localhost:1234/v1',
})
// LM Studioでは複数のモデルも同時に提供できるのでIDを揃える
const model = llmStudio('qwen3-30b-a3b')これだけでOpenAIに課金して使っていたLLMをローカルで動作するQwen3に差し替えられる。
MCP経由でPlaywrightブラウザを動かす
というわけで、MastraとPlaywright MCPサーバーを連携させておき、ローカルLLMをモデルとして 「Open https://notes.ideamans.com/」 などとお願いしてみると、実際にMCP経由でブラウザが起動して目的のサイトを開いてくれる。
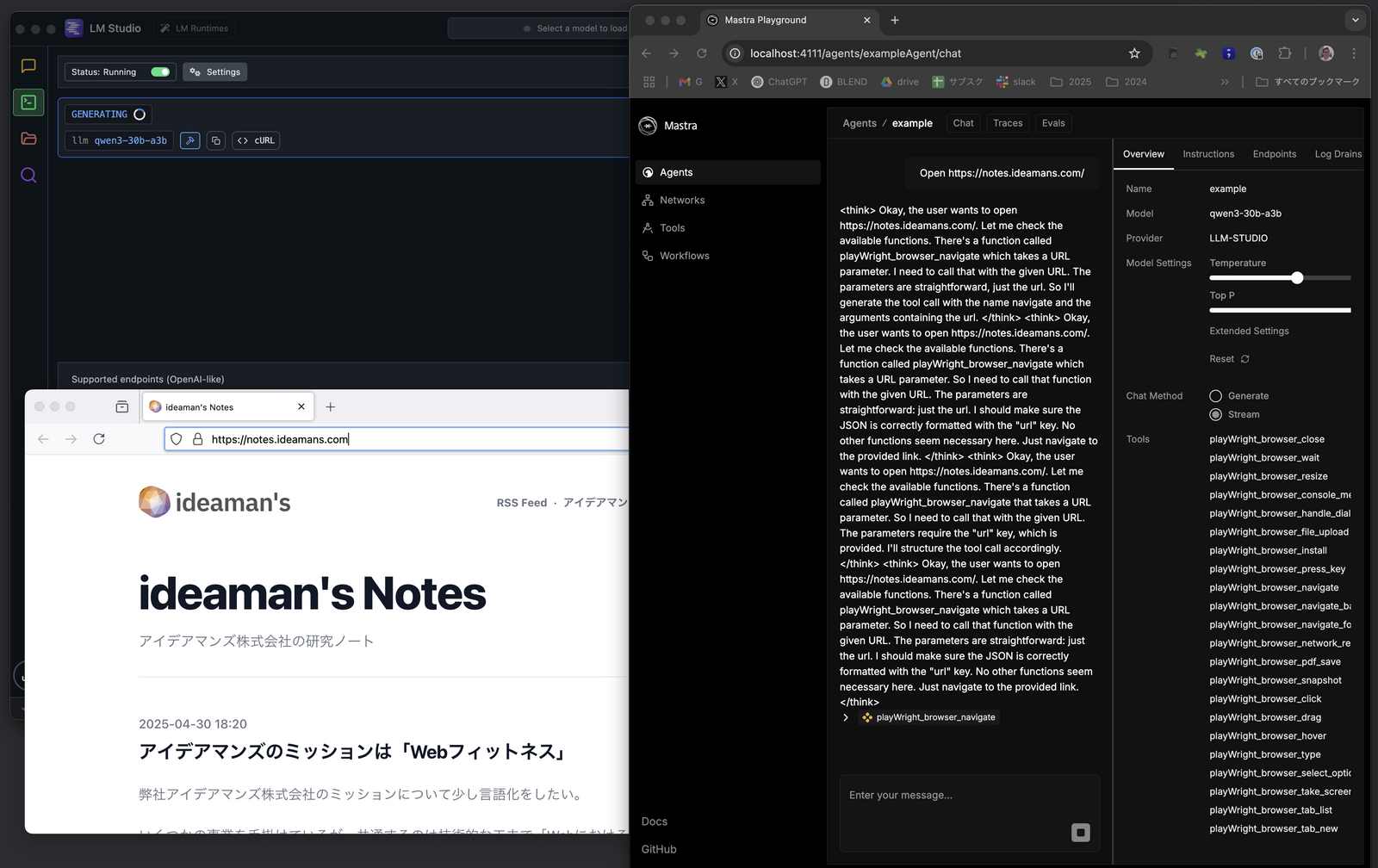
むちゃくちゃLLMの独り言が多い(<think></think>)。
正直、Claude・ChatGPT・Geminiと比べると遅いし、精度も使い物にならないほど低い。
それでも手元のMacbook Proという半導体デバイスにオフラインで自我に芽生えたような感動があった。
それに、API提供されているLLMがどれだけ教育されているのか、どれだけ電気を食っているのか思いを馳せるきっかけになった。
Macbook Proにもファンがある
普段、Macbook Proを使っているとファンの音を聞かない。冷却の必要があるほどCPUが過熱しないし、だからバッテリーも異常なくらい持つ。
しかしLLMを稼働させると、CPU負荷は800%以上にも達し、ブーンという音が聞こえ始める。君にも本当に扇風機がついていたんだ…と驚いた。